
GDC Data Portal
Genomic Data Commons (GDC)는 NCI 1 에서 운영하는 연구 프로그램으로, TCGA, TARGET 등 여러 암 연구 프로젝트로 부터 생성된 genomic data를 저장하고 공유할 수 있는 community 이다. GDC에서 관리하는 데이터는 GDC Data Portal을 통해 다운 받을 수 있다.
GDC Data Portal에서 제공하는 데이터는 자유롭게 이용할 수 있는 ‘open’유형과, 사용 허가가 필요한 ‘controlled’ 유형으로 나뉜다. Raw data나 개인정보에 해당하는 데이터는 controlled 유형이고, 가공된 데이터 (gene expression, masked somatic mutation 등)는 open 유형인듯 보인다 (이곳을 통해서 자세한 정보 확인 가능).
아래는 GDC에서 관리하는 데이터 Level과 Type들이다.
Data Levels
- Level 1: Raw data
- Level 2: Normalized data
- Level 3: Aggregated data
- Level 4: Regions of interest data
- Level 0: No Level
Data Types
| type | level 1 | level 2 | level 3 |
|---|---|---|---|
| Exom-seq | Genome alignment | Mutations | Oncogene vs. Tumor suppressor |
| Whole genome-seq | Genome alignment | Mutations + SV | Translocations |
| RNA-seq | Genome alignment | Digital gene expression | Relative RNA levels, Alternative splicing |
| Copy number | Data segmentation | Copy number calls | Gene amplification/deletion |
이렇게 다양한 데이터를 관리 해야하다보니까 Data 구조를 정밀하게 설계할 필요가 있겠다는 생각이 들었다. 아래는 GDC Data 모델이다. 엄청나다. (1-2년만에 이런 체계적인 구조가 뚝딱 만들어 지진 않았을 꺼고, 오랜 시행착오의 결과이겠지…)
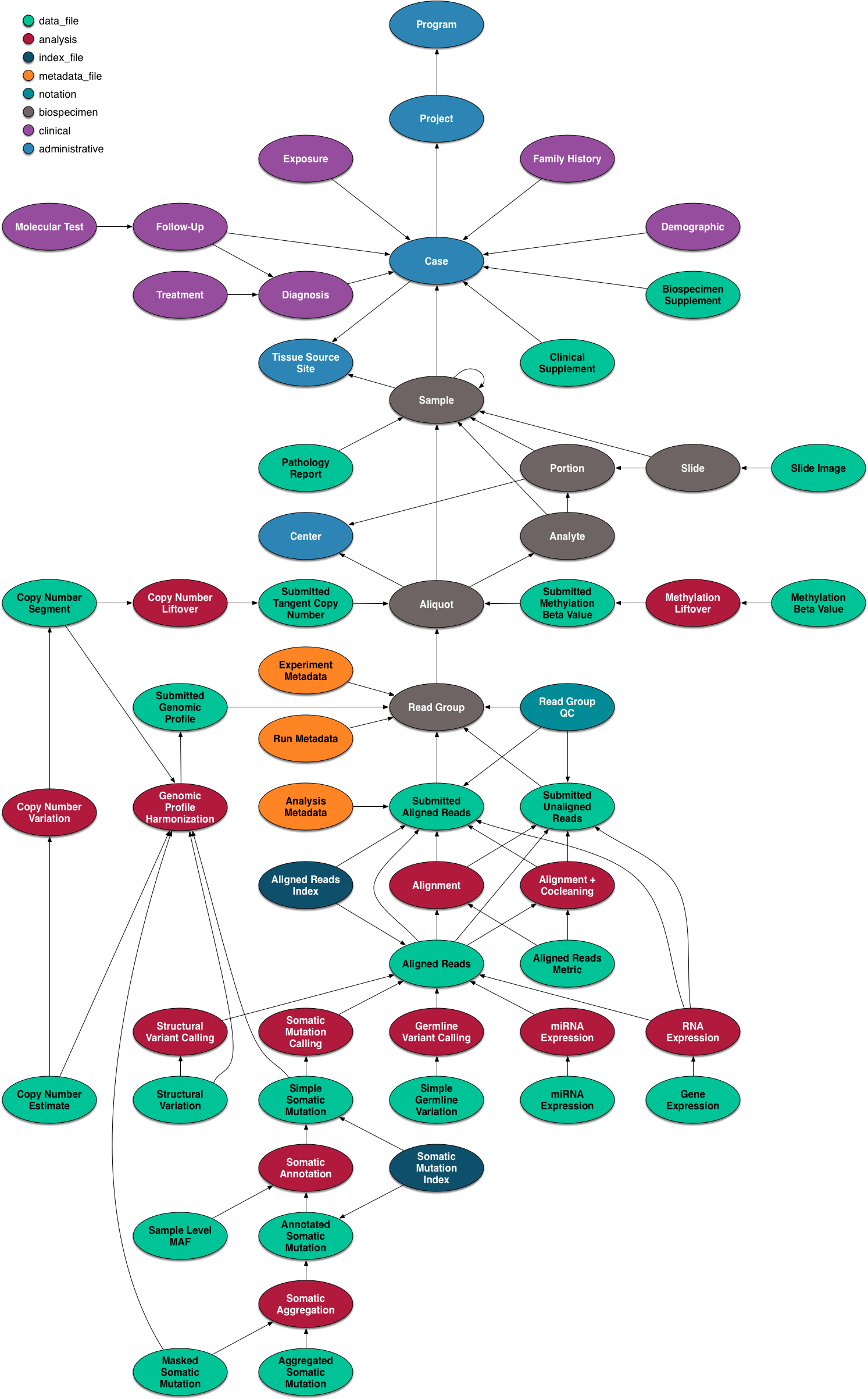
GDC Data Model (from GDC hompage)
연구소에서 다양한 in-house 데이터를 축적하다보면 GDC Portal과 같은 역할을 하는 자체 repository 구축이 필요하다는 생각을 하게된다. 그 때 이미 잘 만들어져 있는 GDC Portal, cBioPortal 같은 프로젝트를 벤치마킹하면 좋을 것 같다.
References
- GDC Documentation: https://docs.gdc.cancer.gov/
Note
-
National Cancer Institute의 줄임말, National Institutes of Health (NIH)의 한 파트 ↩